Ben Smithgall
Welcome to the web blog




Bit pusher at Spotify. Previously Interactive News at the New York Times, U.S. Digital Service, and Code for America.
Visualizing a generalized maximum-weight-matching graph algorithm
March 10, 2026
I have a small side project I’ve been tinkering with over the past few years: a chess tournament management application. It’s been nice as a sort of open-ended exploration sandbox for all sorts of different things, like learning Phoenix, and getting to implement the rules of chess.
The core of the application involves tournament matchmaking. I’ve added support for various tournament formats over the years, but I started with the most common chess format: swiss. The application for matchmaking in Swiss tournaments can be understood best as a form of a maximum-weighted matching problem. The players form a graph (often bipartite, but not necessarily!), and we use the state of the tournament to determine the weight of the edges between them. Internally, the application assigns weights based on rules from the USCF rulebook.
For a very long time, the application used a very-slightly modified version of Joris van Rantwijk’s implementation. Elixir makes it pretty easy to shell out calls to other languages and get the results back, and I just used this. The algorithm itself is quite complicated and I always had trouble reading and deeply comprehending it. Joris has a great writeup of how it works.
I had tried a couple of times to port the algorithm directly from Python to Elixir. I tried by hand and wasn’t able to make much progress. I also tried using LLMs to help with this transformation, but I had never been able to make much headway.
However, with the release of Opus 4.5 and Opus 4.6, I decided to give it another go. I asked Claude to read and build a spec and implementation plan to move things over, and it pretty much just worked. This was the first time an LLM was able to really tackle this problem in a serious way.
So for this, I wanted to go a bit further into the verification and validation. The algorithm is very complicated with many moving pieces. I had a lot of trouble deeply understanding it. So I put together this visualization with Claude.
Working with Claude on this was interesting. It can produce visual and written artifacts very quickly, but the comprehensibility of those artifacts is wildly hit-or-miss. Working from the original spec documents and the writeup had steered Claude into a spot where the words produced assumed a pretty deep familiarity with linear programming and some algorithm-specific jargon. Given that the goal was to produce something somewhat comprehensible, this didn’t really work out. I was trying to thread a needle here: existing explanatory resources I had found (like from wolfram or TUM in munich) operated at either too high or too low of a level; I wanted something that was a lot more explicit, but still approachable. For the top-level algorithmic explanation, I had to throw away basically everything it wrote. After a lot of turns, though, I got something I was pretty happy with:
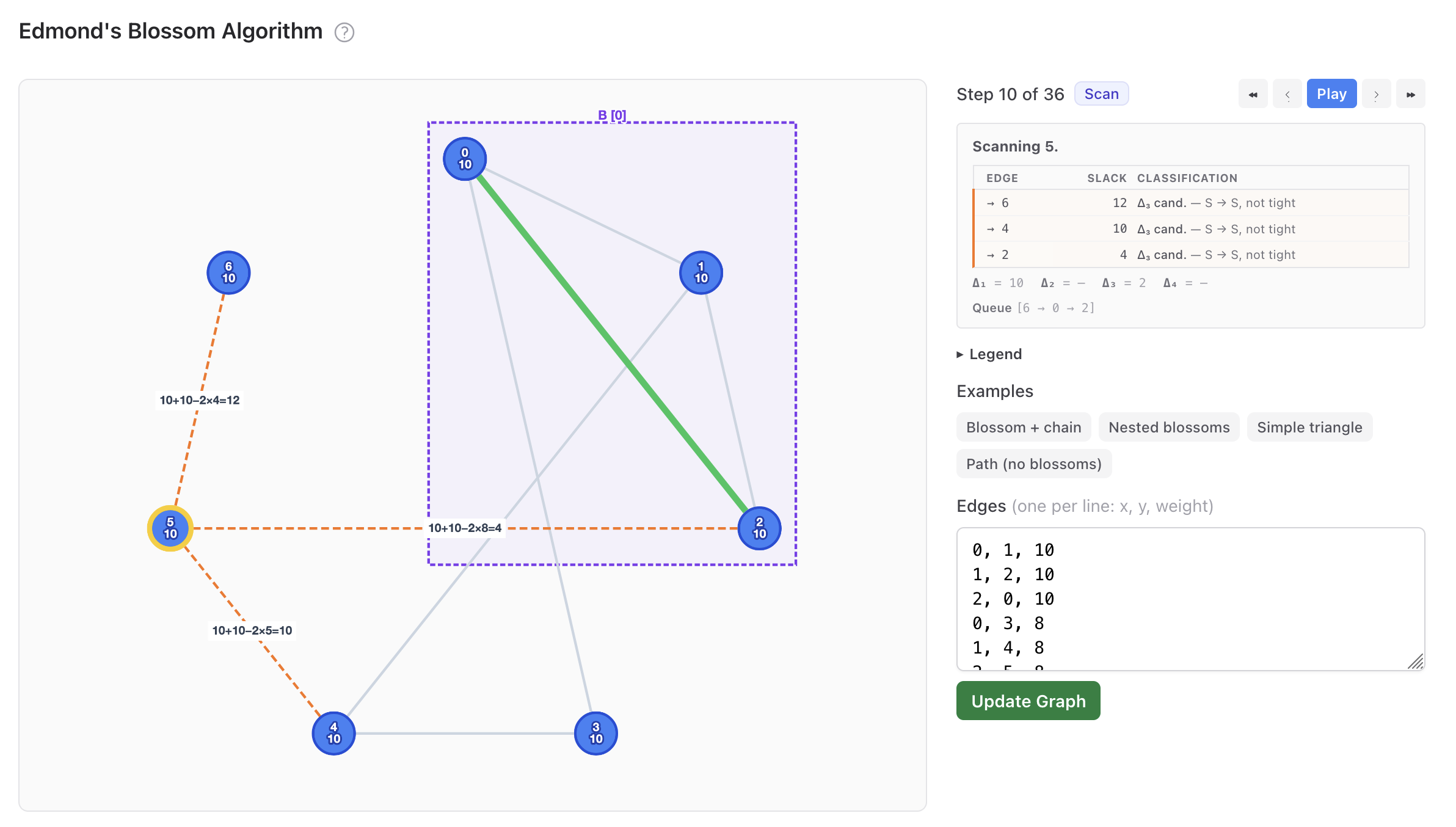
This visualization is backed by a Phoenix LiveView that uses the actual implementation that runs in the application with some additional observability attached. This allows for a lot of control over what data is visualized, including specific details about internals of the algorithm:

Because it’s built directly into the application, one other nice thing is the visualization also serves as a nice debugging tool: I added some code to deserialize graphs out of the URL state, which lets me walk through how the pairing works for basically any tournament:

Clauding
I’m not going to talk too much about the rise of Anthropic’s flagship model for generating code as there is a ton of pre-existing writing about its capabilities. For me, if you can gain this level of coding capability, the main interesting question is around what do you do with the time that you have gained? I think that using “agentic LLMs” (something like Claude code) are a bit of a manic technology: they produce lines that often compile and work very quickly! So what to do about this? I see basically two paths: spend tokens to make things quickly (aka slop), or spend tokens on deep verification and learning.
A lot has been written about building novel systems without really having an understanding about how they work, and whether or not that’s actually a good thing. Perhaps you can build giant towers of abstraction, but that isn’t necessarily required from the tools. I think that instead going in this direction of using the capability for improving what existings or learning more deeply is much more interesting. Of course, in a personal project it’s much easier to take this time; I am more incentivized to build these sorts of tools for learning and understanding: the process of building out the visualization did help me more deeply understand the algorithm.
Working at the edge of my own understanding with LLMs is also quite strange; it’s easier to pilot Claude through familiar domains and problems. Looking at its output is helpful but because those problems have a familiar shape it’s more akin to working with a colleague. In this scenario, though, I knew that the output was correct (one of the original implementation details was building out a big validation suite that tested tens of thousands of graphs against the reference implementation) but didn’t really know why. The process of building this visual artifact helped me to understand why in a way that I don’t think would have been possible previously.